
プログラミングの際、正規表現を使用してファイルから特定のパターンを持つ文字列を抽出する処理を書くことがあると思います。
本記事のサンプルコードでは、指定されたHTMLファイルから<a href=”…”>タグを見つけ、その中のURLをコンソールに出力します。
入力ファイルと出力例
入力ファイル(HTML)
<!DOCTYPE html>
<html>
<head>
<title>Sample HTML Page</title>
</head>
<body>
<h1>Welcome to My Website</h1>
<p>Visit <a href="https://www.example.com">Example</a> for more information.</p>
<p>Check out <a href="https://www.anotherexample.com">Another Example</a> as well.</p>
</body>
</html>出力例
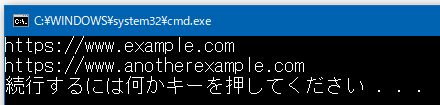
サンプルコード
指定されたHTMLファイルから<a href=”…”>タグを見つけ、その中のURLをコンソールに出力します。
using System;
using System.IO;
using System.Text;
using System.Text.RegularExpressions;
class Program
{
static void Main(string[] args)
{
string htmlFilePath = @"C:\path\to\your\file.html"; // HTMLファイルのパス
try
{
using (StreamReader reader = new StreamReader(htmlFilePath, Encoding.UTF8))
{
string line;
while ((line = reader.ReadLine()) != null)
{
// 正規表現で<a href="...">タグ内のURLを抽出
foreach (Match match in Regex.Matches(line, @"<a\s+href=""([^""]*)"">"))
{
string url = match.Groups[1].Value; // URLの抽出
Console.WriteLine(url);
}
}
}
}
catch (Exception ex)
{
Console.WriteLine("An error occurred: " + ex.Message);
}
}
}
- StreamReaderを使用してHTMLファイルの読み込みを行います。UTF-8エンコーディングを指定しています。
- Regex.Matchesメソッドを使用して、各行に含まれるリンクタグを検索します。正規表現によりタグの中のURLをキャプチャします。
- match.Groups[1].Valueを使用して、各リンクタグからURLを取得し、コンソールに出力します。
まとめ
本記事では、正規表現を使用し、特定のパターンを持つ文字列を抽出する方法を紹介しました。